
The NVLink Switch System, developed by NVIDIA, stands as a backbone of modern high-performance computing (HPC) and artificial intelligence (AI) infrastructure, revolutionizing how data is transferred across complex computational environments. As AI models grow to trillions of parameters and scientific simulations demand unprecedented computational power, the need for high-speed, low-latency interconnects has become paramount. NVIDIA’s NVLink technology, a high-bandwidth, point-to-point communication protocol, addresses this by enabling direct, rapid data exchange between GPUs and CPUs. The NVLink Switch System extends this capability, connecting multiple NVLink-enabled servers into a cohesive, high-performance GPU fabric that supports massive scalability and unparalleled data throughput for the most demanding workloads.
This advanced system transforms data centers and supercomputers into highly efficient computing clusters, capable of handling tasks such as training large language models, conducting climate simulations, or powering cutting-edge research. By providing up to 14.4 terabytes per second of non-blocking switching capacity and supporting up to 576 GPUs in a single rack, the NVLink Switch System ensures seamless all-to-all communication, making it a vital component in applications where performance bottlenecks can hinder progress. This article explores the technical specifications, real-world applications, and significance of the NVLink Switch System, highlighting its role in shaping the future of AI and HPC.
Understanding NVLink
NVLink is a proprietary, wire-based, serial multi-lane interconnect developed by NVIDIA, first announced in March 2014. Unlike traditional PCIe interconnects, which rely on a central hub for communication, NVLink employs a point-to-point mesh networking approach. This allows for direct chip-to-chip communication, significantly reducing latency and increasing bandwidth. NVLink is designed specifically for data and control code transfers between CPUs and GPUs, as well as between GPUs, making it ideal for data-intensive workloads.

Evolution of NVLink
NVLink has evolved through several generations, each improving bandwidth and efficiency:
| Generation | Architecture | Data Rate per Link | Total Bandwidth per GPU |
|---|---|---|---|
| NVLink 1.0 | Pascal | 20 GB/s | Up to 80 GB/s |
| NVLink 2.0 | Volta | 50 GB/s | Up to 300 GB/s |
| NVLink 3.0 | Ampere | 50 GB/s | Up to 300 GB/s |
| NVLink 4.0 | Hopper | Enhanced bandwidth | Not specified |
| NVLink 5.0 | Blackwell | 100 GB/s | Up to 1.8 TB/s |
The fifth-generation NVLink, introduced with the Blackwell architecture, supports up to 18 connections per GPU at 100 GB/s each, achieving a total bandwidth of 1.8 terabytes per second (TB/s). This is twice the bandwidth of the previous generation and over 14 times that of PCIe Gen5, making it a game-changer for multi-GPU systems.
The NVLink Switch System
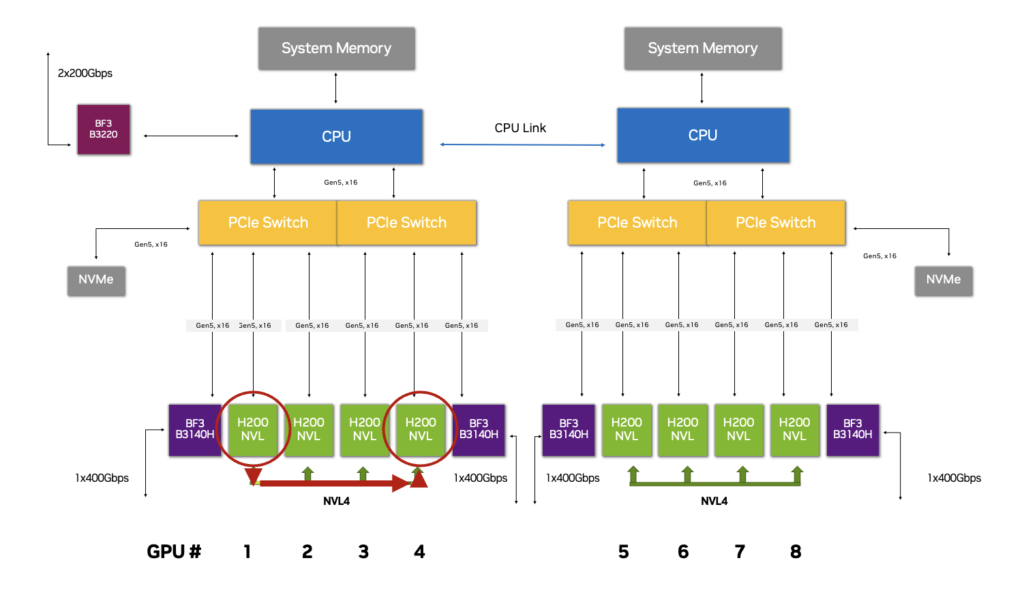
The NVLink Switch System extends the capabilities of NVLink by enabling high-speed communication across multiple nodes. It connects multiple NVLink-enabled servers into a large, unified GPU fabric, effectively creating a data-center-sized GPU cluster. This system is crucial for scaling AI and HPC applications that require massive parallel processing.
Key Features
- High Bandwidth: The NVLink Switch supports up to 144 NVLink ports with a non-blocking switching capacity of 14.4 TB/s.
- Scalability: It can interconnect up to 576 fully connected GPUs in a non-blocking compute fabric, enabling massive scalability.
- All-to-All Communication: Every GPU can communicate with every other GPU at full NVLink speed, both within a single rack and across racks.
- SHARP Protocol: Incorporates NVIDIA’s Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) for in-network reductions and multicast acceleration, optimizing data aggregation and transfer.
Technical Specifications
| Feature | Specification |
|---|---|
| Bandwidth per GPU | Up to 1.8 TB/s (NVLink 5.0) |
| Connections per GPU | Up to 18 NVLink connections (Blackwell GPU) |
| Switch Capacity | 14.4 TB/s non-blocking switching capacity |
| GPU Support | Up to 576 GPUs in a single rack |
| Port Configuration | 144 NVLink ports via 32 OSFP cages (SGXLS10 Switch) |
| Per-Link Bandwidth | 26.5625 GB/s (NVLink 4.0, SGXLS10 Switch) |
The NVLink Switch System is designed to work seamlessly with NVIDIA’s latest GPU architectures, such as the Blackwell Tensor Core GPU. For instance, in the NVIDIA GB300 NVL72 system, the switch enables 130 TB/s of GPU bandwidth, supporting 72 GPUs that function as a single high-performance accelerator with up to 1.4 exaFLOPS of AI compute power.
Comparison with Other Interconnect Technologies
To fully appreciate the NVLink Switch System’s capabilities, it’s useful to compare it with other interconnect technologies commonly used in HPC and AI environments:
| Technology | Use Case | Bandwidth | Latency | Strengths |
|---|---|---|---|---|
| NVLink | Intra-node GPU communication | Up to 1.8 TB/s per GPU (NVLink 5.0) | Low | High bandwidth, low latency for GPU-to-GPU and GPU-to-CPU communication |
| PCIe Gen5 | General-purpose peripheral interconnect | Up to 128 GB/s (x16 lanes) | Moderate | Versatile, widely used, but lower bandwidth than NVLink for GPU communication |
| InfiniBand | Inter-node communication in HPC clusters | Up to 400 Gb/s (NDR) | Low | High bandwidth, low latency for cluster-wide communication |
| Ethernet | General-purpose networking | Up to 400 Gb/s (400GbE) | Higher than InfiniBand/NVLink | Ubiquitous, supports RoCE for high-performance workloads |
- PCIe: While PCIe is versatile for connecting various peripherals, its bandwidth (128 GB/s for PCIe Gen5 x16) is significantly lower than NVLink’s 1.8 TB/s per GPU. NVLink is optimized for direct GPU-to-GPU communication, making it superior for intra-node tasks.
- InfiniBand: InfiniBand is a high-performance interconnect for inter-node communication in HPC clusters. It complements NVLink in systems like Summit and Sierra, where NVLink handles intra-node communication and InfiniBand manages inter-node connectivity.
- Ethernet: Ethernet, even with high-speed variants like 400GbE or RoCE (RDMA over Converged Ethernet), generally has higher latency and lower bandwidth than NVLink for GPU-specific tasks. It is better suited for general-purpose networking.
NVLink’s strength lies in its specialization for intra-node GPU communication, while InfiniBand and Ethernet excel in broader networking scenarios.
Real-World Applications
The NVLink Switch System is a backbone of modern HPC and AI infrastructure, enabling a range of applications:
- AI Training and Inference:
- The system is critical for training large language models (LLMs) with trillions of parameters, which require massive compute and memory bandwidth.
- The NVIDIA GB300 NVL72 system, for example, uses NVLink switches to connect 72 GPUs, providing 130 TB/s of bandwidth and enabling up to 1.4 exaFLOPS of AI compute power. This allows researchers to tackle complex AI models efficiently.
- Supercomputers:
- Supercomputers like Summit and Sierra, developed for the US Department of Energy, utilize NVLink for intra-node CPU-GPU and GPU-GPU communication. InfiniBand complements this by handling inter-node connectivity, creating a hybrid architecture for maximum performance.
- Scientific Simulations:
- In fields such as climate modeling, fluid dynamics, and materials science, simulations demand vast computational resources. The NVLink Switch System enables efficient data sharing between GPUs, accelerating these computations.
- Data Centers:
- For large-scale data processing and analytics, NVLink Switch Systems create high-performance computing clusters. They enable data centers to handle big data workloads with unprecedented efficiency by providing a unified GPU fabric.
Future Implications
As the demand for computational power grows, particularly in AI and HPC, the need for faster and more efficient interconnects will intensify. NVLink’s evolution from its first to fifth generation demonstrates NVIDIA’s commitment to addressing these challenges. Future developments may include:
- Increased Bandwidth: Further enhancements to support exascale computing, potentially exceeding 1.8 TB/s per GPU.
- Reduced Latency: Continued improvements in latency to optimize real-time applications.
- Advanced Protocols: Enhancements to protocols like SHARP for more efficient data aggregation and transfer.
The NVLink Switch System is poised to play a pivotal role in enabling the next generation of computing systems, from AI supercomputers to advanced scientific research platforms.
Conclusion
The NVLink Switch System is a transformative technology in the realm of high-performance computing and artificial intelligence. By providing high bandwidth, low latency, and unparalleled scalability, it enables the creation of powerful, unified GPU fabrics capable of tackling the most demanding computational challenges. Its ability to support all-to-all communication across hundreds.






